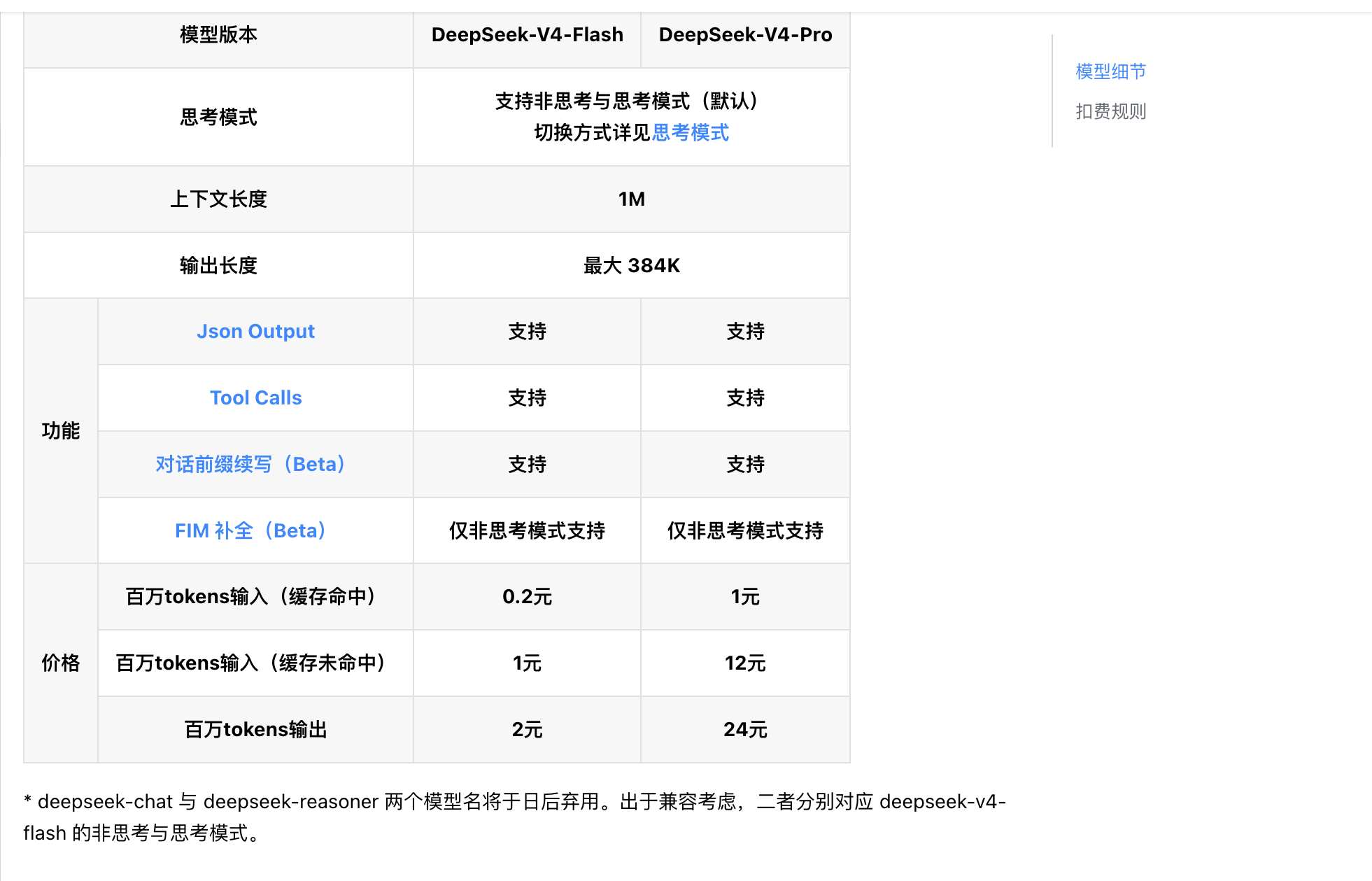
华为 Pura X Max 深度体验:比起「阔折」,「主动式 AI」更吸引我

作者|张勇毅
用 Pura X Max 的第三天,我同时做了两件以前不会在同一台设备上做的事。
早上通勤的时候,我合着盖、单手握,读完了一篇 8000 字的长文。中午回到工位前,把它展开当成一个平板来使用。
中间没有切换任何设备。
这是 Pura X Max 跟它前一代 Pura X 最大的不同。Pura X 仍然是一台『屏幕比例改了一下』的手机,Pura X Max 已经不是了——它合上是手机,展开是一台能装进口袋的小平板。
01
上一代 Pura X 的「奇观」
去年 Pura X 上市之后,小红书上慢慢沉淀出一种很有意思的玩家文化——主要是女性用户,她们买了 Pura X 之后会再配一个固定的硬壳,把它常态锁在展开状态下使用,几乎不合上。简单来说,就是把这台一万元的折叠屏,当成一台屏幕比例特殊的直屏机来用——只不过这台『直屏机』的屏,是一块 √2:1 的大屏。
她们在小红书上互相分享这种用法的体验:屏幕比例完美适配 4:3 拍出来的照片、看小红书笔记一屏能多两条、读电子书时跟一本平装书的版心宽度几乎一致——所有这些场景,都因为这块屏的比例对了,自然落了进来。
这个用法听起来挺反常,但它从一个非常诚实的角度,说明了一件事:Pura X 的内屏体验太耀眼了——耀眼到一部分用户愿意放弃『折叠』这个功能本身,只为了让这块屏一直处于最完整的形态。
这件事的反讽意味在于——折叠屏过去七年的核心叙事,是『同一台设备的两种形态』,是『手机和平板二合一』。所有厂商的发布会上,最高光的镜头永远是机身合起或打开的那个瞬间。但 Pura X 的部分用户用脚投票投出来的结论是:他们要的不是『二合一』,是那块比例对了的大屏。 至于折叠这件事,反而被她们当成了一个累赘——既然展开的形态这么完美,为什么还要给它留一个变小的可能性?
Pura X 本身是成功的。年销量做到 150 万台,对至今仍然售价相对较高的折叠屏来说不是小数字。这个成功本身就证明了 √2:1 的内屏方向走对了——对到用户甚至愿意为它牺牲掉折叠功能。
但这个成功也留下了一个新问题:当内屏好到让用户不想合盖,外屏的存在意义是什么?

而 Pura X Max 这一代,华为想接着回答的就是这个被留下的问题。
02
Pura X Max 的内屏,长成了一台小平板
Pura X Max 的内屏是 7.7 英寸,比例 √2:1(也就是 A4 纸的长宽比)。这块屏铺开来,对角线已经非常接近 iPad mini 的 8.3 英寸——两者落到桌面上,是同一个量级的视觉体量。
关键的不是尺寸,是它做的事变了。
Pura X 的内屏虽然耀眼,但它做的事仍然属于『手机』这个品类——只是用一块更舒展、比例更合理的屏在做手机日常的事而已。这是为什么小红书上那批用户愿意把它锁在展开状态使用——它是『手机这个品类里最舒服的那一种』,但它没有跨过手机的边界。
在 Pura X Max 上展开内屏,事情跨过去了。

Pura X Max 的内屏分成两半之后,每一半还有接近常规手机外屏的可用宽度;这意味着如果你愿意的话,你仍然可以把它当做一个平板来分屏,同时使用两个 App——这对于很多折叠屏用户来讲,可能是一个更熟悉的操作逻辑。

剪映的体验也有结构性的不同。剪一段竖向的 Vlog,左边是预览区,右边是时间轴和素材库,工具栏不用滑动就能全局展示。手写笔轻按可以唤出波轮菜单,切片、调速、加字幕一气呵成。过去我在手机上剪视频是一种「赶时间的妥协」——内容能发出去就行,质量要求降低一档;现在它接近一种正经的工作流。
差别是结构性的。Pura X 的内屏让你「把手机的事做得更舒服」,Pura X Max 的内屏让你「做手机过去做不了的事」。
前者是手机的极致,后者是平板的开端。这就是为什么华为一直在强调,Pura X Max 并非 Pura X 的替代品,而是两个完全不同的品类。
过去手机谈生产力一直有点尴尬——你可以在手机上写字、画图、剪辑,但每一件事都伴随着一种「将就」的体感:屏幕不够、空间不够、视野不够。Pura X 缓解了这种将就感,Pura X Max 把它彻底拿掉。一件事开始之后你不会想着「等我回家用 iPad 再认真做一遍」,而是这一遍就把它做完。
把内屏做成小平板,本身不是最难的——把它做大就行了。
真正难的是:在内屏跨过手机边界变成小平板之后,让合盖的形态依然有自己不可替代的价值,不再像 Pura X 时代那样被『耀眼的内屏』盖过去。

Pura X Max 这一代要解决的,正是这个被 Pura X 留下的悬而未决的问题——让合盖形态有自己的独立价值,让展开和合盖不是同一件事的两种尺寸,而是两种不同的使用类别。
它的解法不是去『修复』合盖(合盖的外屏其实从 Pura X 那一代起就已经合格了),而是从两个方向同时拉开两个形态的距离:
展开侧,给它增加合盖时做不了的事。 7.7 英寸的内屏长成小平板之后,画图、双栏写作、剪辑视频这些事变成了『展开才能做』的事——它们是合盖外屏因为物理尺寸而做不了的事。展开有了独立价值。
合盖侧,让 5.4 英寸的外屏继续延续 Pura X 那块大家认可的好用性——单手握持的边界、口袋里的便携性、走路通勤时随手就能用。 这些是展开形态因为尺寸过大而做不到的事。合盖也有了独立价值。
我用 Pura X Max 的这一周,外屏使用时间占了日常使用的 80% 以上。这跟我用 Pura X 的体感很不一样——Pura X 时代我会主动选择展开,因为展开形态本身就更舒服;Pura X Max 时代我大部分时候不展开,因为合盖已经够用,展开是有了具体目的之后的选择。
读微信公众号的一篇长文,文字落在外屏上,行宽接近一本平装书的版心——我读完一屏的速度比在 iPhone 上要快一些,不是因为屏幕大,是因为眼睛不用频繁返回到左侧。
刷小红书的摄影类笔记,外屏一屏能横向铺开两到三张缩略图。要决定一张图值不值得点开看大图,扫一眼就够。
刷 B 站的横向视频,画面横向铺满,几乎没有上下黑边。
这些是手机的事,外屏完成;画图、双栏、剪辑这些是平板的事,内屏完成。 两块屏不再互相覆盖,也不再互相代偿——它们分别承担了不同类别的使用。
这也是过去七年折叠屏一直没做到的事。
实现这件事的底层支撑,除了硬件设计上的取舍,还有 HarmonyOS 几年下来积累的多设备适配能力。一块外屏比例的应用,展开后能丝滑切换成接近平板的版式;分屏的两个区块,应用能各自独立地按比例渲染——这些事情看起来像是顺理成章,但放在 Android 阵营里看,没有几家能做到这种程度的应用一致性。这是华为愿意把外屏和内屏都做认真的底气来源——他们知道软件能跟上。
03
第一台 AI 不需要「召唤」的手机
回到产品形态本身,我们都知道,「阔折叠」只是一个起点,它并不是对于「折叠屏是用来干什么的」真正的回答。 而华为在这个起点之上,想给出的新回答就是「小艺伴随式 AI」。
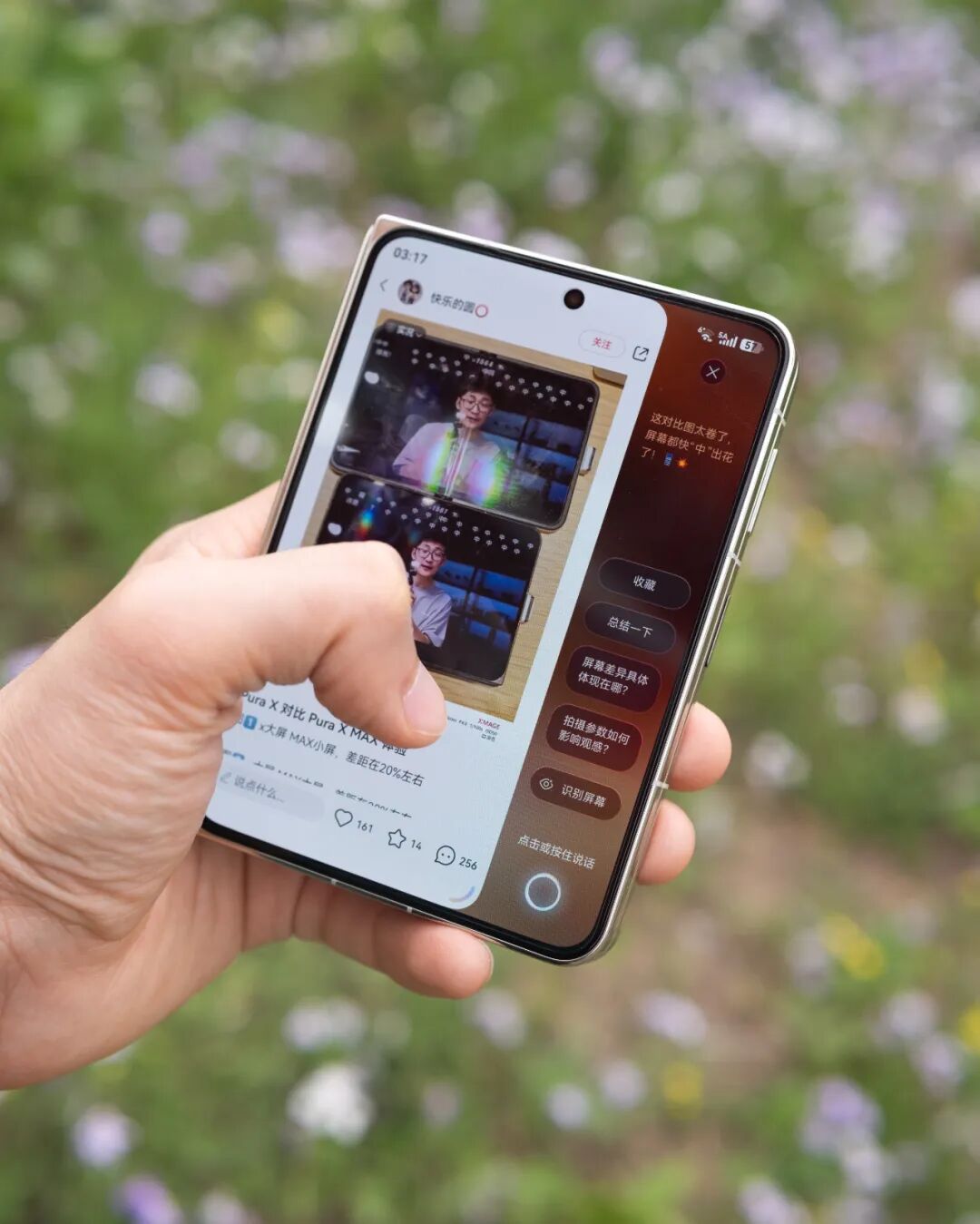
Pura X Max 把小艺伴随式 AI 放成了屏幕右侧的一条常驻窄栏。主内容收窄到大概常规手机的宽度,小艺占据剩下的空隙,两者并行存在,互不打扰。要它的时候它就在,不用召唤、不用切应用、不用喊唤醒词。
这个位置,在过去任何一台手机上都没有过。
AI 真正进入消费产品就是这两三年的事,但手机的交互范式在二十年前就已经定型——主屏、应用图标、点进 App、一个 App 占一整块屏幕。这套范式里从来没给 AI 留位置。所以过去这一两年厂商把 AI 装进手机的时候,能做的选择不多:做成一个独立的 App、塞进下拉菜单、做成长按电源键唤起的浮窗。AI 在手机里始终是被「召唤」的——你先想到它,然后去找它,然后它出现,然后它消失。
Pura X Max 是我用过的第一台不需要「召唤」AI 的手机。
写稿这件事的体感变了:左边一个文档窗口,右边一条小艺侧边栏。读到一个我不确定的参数,直接选中,小艺立刻在侧边给出解释——不用切到浏览器,不用打断写作的状态。读到一段需要补查资料的内容,小艺会主动建议可以延展的方向。整个过程像是右手边坐了一个安静的助手——他知道我在做什么,但只在我看向他的时候开口。

华为 Pura X Max
读小红书的时候是另一种感受。刷到一个不错的摄影点位,过去的操作是截图、保存、下次想用的时候自己翻相册。小艺伴随式 AI 把这一步省了——它能直接识别屏幕上的内容,把地点、时间、构图建议帮你整理好,加进待办。截图是把信息从屏幕里搬出来,小艺是在屏幕里把信息消化掉。
这件事的本质,不是因为模型变得多强,是因为 AI 第一次在手机里有了一个属于它的物理位置。
在直板手机上,AI 一直是被「借用」的——它借用浮窗、借用通知栏、借用某个角落里临时塞进去的按钮,每一次出现都是过路。Pura X Max 给了它一块属于自己的常驻领地。AI 从工具箱里的一把工具,变成了使用环境的一部分。
影像部分,Pura X Max 的第二代红枫影像系统,是我用过的折叠屏里第一台没让我感觉到这个让步的设备。
主摄是 5000 万像素 1/1.56 英寸的传感器,配了一颗 F1.4-F4.0 的十档物理可变光圈——这个配置过去只在直板旗舰上见过。十档可变光圈意味着你能像用真正的相机那样手动调浅景深或大景深,不是计算摄影模拟出来的虚化,是镜头物理收放的虚化。




真正让我意外的是长焦。5000 万像素的 3.5 倍潜望,最大支持 100 倍变焦——这是一颗几乎不该出现在折叠屏上的长焦。过去我用折叠屏拍演唱会、拍发布会现场,都得提前接受「拍不清楚」的预期;这一周拿 Pura X Max 试拍,10 倍以内的画面是干干净净的,没有过去 AI 长焦那种典型的「涂抹纹路」,建筑物的边缘锐利、树叶不糊。






Pura X Max 实机样张:摄影师:FlyingFist
说完了优点,目前关于 Pura X Max 的一些槽点,我觉得也有必要和大家分享一下:第一个是单手操作的边界。85mm 的外屏宽度,比常规直板手机的 75mm 多了一截。我手不算小,单手回消息、刷信息流、看视频都没问题,但要点屏幕另一侧的按钮,得换个握法或者用左手辅助。如果你手偏小,这台手机更接近一台「需要双手」的设备。
第二个是相机模组。三摄横向排开的 Deco 块体积不小,机身展开后竖着拿,重心明显偏上。陶瓷边框的质感很好,但凸起也确实夸张。这是为了塞进 50MP 潜望长焦付出的代价。
第三个是续航。外屏好用是把双刃剑——我在外屏上消耗的时间比预期更多,5300mAh 的电池一天一充压力不大,但也没什么富余。如果你对它的期待是重度使用,一定记得带块充电宝。
04
折叠屏下一程
回过头看,Pura X 和 Pura X Max 走的是同一条产品线,但解决的是两个不同的问题。
Pura X 解决了「折叠屏的内屏可以是一块用户愿意一直用的大屏」。Pura X Max 解决了「折叠屏的内屏可以是一台真正的小平板,与此同时,让合盖形态从『内屏的影子』里走出来,变成一种独立的使用类别」。
这两件事加起来,指向的不是一个「更大的折叠屏手机」,而是一个过去并不存在的设备类别:能装进口袋的小平板。
这个判断会被后续市场进一步验证。传闻中的折叠屏 iPhone 据说也会用接近 √2:1 的比例,三星、小米也都在跟进。一旦比例成为共识,比的就不再是「谁的内屏更大」,而是:谁能在做出小平板的同时,让合盖形态依然是一台你愿意单手拿出来用的手机。
这件事比想象中难。它要求厂商同时在两个完全不同的产品逻辑下做对——平板的逻辑和手机的逻辑——并且让它们共用一套硬件、一套系统、一套生态。Pura X Max 之所以能做到,背后是 HarmonyOS 几年积累下来的多设备适配能力。换一家厂商不一定能短期内追上。

苹果是这个赛道最值得关注的变量。一旦折叠屏 iPhone 真的落地,它会带着 iPad 多年沉淀下来的 iPadOS、Pencil、Magic Keyboard 整套生产力生态进场。这是华为目前还没完全展开的牌——HarmonyOS 在多设备协同上做得很扎实,但生产力生态的丰富度还有空间。Pura X Max 拿出的这一手「口袋小平板」,本质上是在替整个 Android 阵营抢一个时间窗口:在苹果带着完整生态进场之前,把这个新品类的标准先立下来。
如果一年后再回头看,能在折叠屏市场拉开身位的产品,比拼的不是参数表,是这套「双身份」的完成度。
合着,是一台我愿意带出门的手机。打开,是一台我愿意工作的小平板。
折叠屏走过七年,这是第一次。