深扒Minimax与智谱:大模型,一场算力强度与融资耐力的残酷绝杀?
文 | 海豚研究
26年初ChatGPT发布三年之际,中国两大AI大模型创业公司Minimax和智谱几乎同时,均以大约60亿美金的估值上市,且上市后都以暴涨,并带动整个AI应用的普涨行情。但同时,扒开两个大模型公司的报表,都是“亏无止境”的面相。
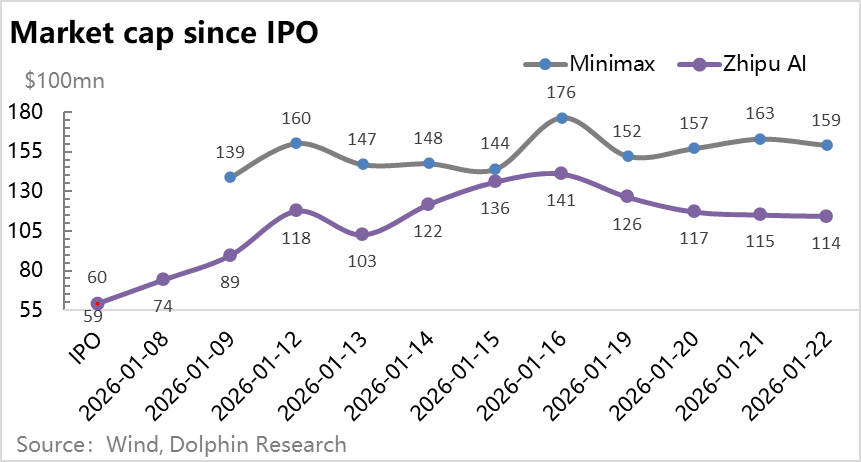
一边是全球大模型疯狂卷价格、越来越多大宗商品,一边是模型无底洞的研发投入,但同时还有这种即翻倍的盛景。冰火交织下,海豚君一直的疑问是大模型到底是一种什么样的生意。
这次,海豚君就结合两个上市的公司数据,来认真探讨一下这个问题:
1)大模型到底需要怎样的投入要素和密度?
2)算力到底扮演了什么角色?
3)模型经济学如何算,才能平衡?
4)最终,大模型到底是怎样的生意模式?
以下是详细分析:
一、拔高的收入、惊悚的投入
两个大模型公司Minimax和智谱,都是“短小精悍”型——人手少、产品迭代快,收入增长快。人数到2025年下半年没超一千人,收入零起步,两三年年化收入都在快速迈向一亿美金。
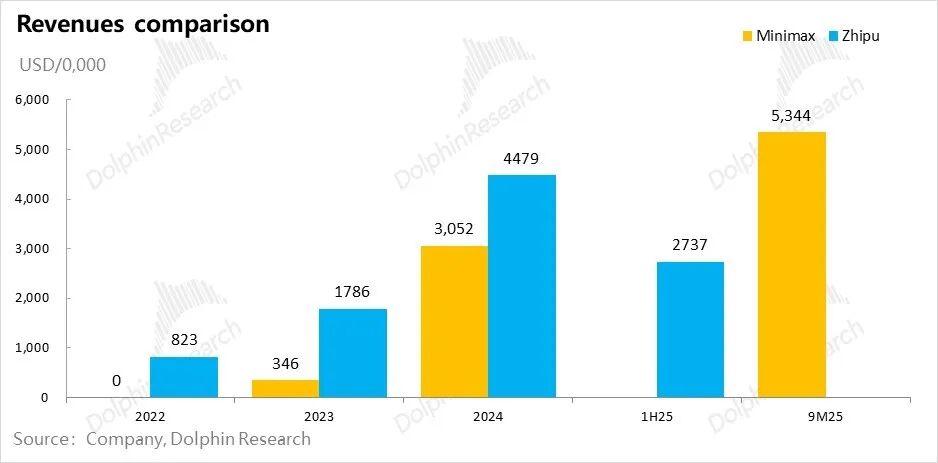
但到了支出层,再高增的收入都被凶猛的投入比得相形见绌:即使收入增长过程中,Model to B公司智谱持续保持在50%的高毛利,还是Model to C公司Minimax毛利率翻正。
2024年两个公司的支出(成本与运营开支)加总基本在当期收入的10倍上下。Minimax 2025年前九个月收入快速做大后支出仍然是收入的5倍以上;而智谱到了2025年上半年看起来反而更加规模不经济了。
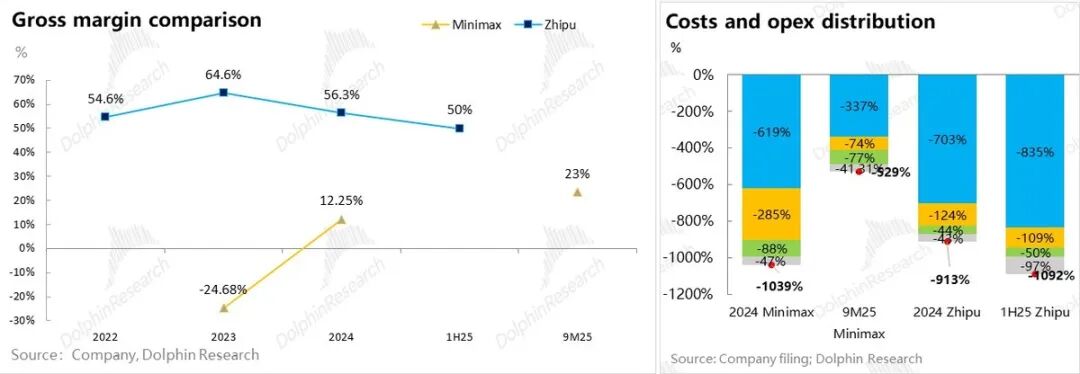
这里的核心问题是,对于模型公司而言,到底收入越大、亏损率收窄,还是收入越大、亏损率越高的规模不经济结局?
模型经济学的底层三要素——数据、算力、算法,大家已耳熟能详。但要解答模型到底适不适用互联网规模经济规模,关键是理解大模型到底需要怎样的投入密度。
在大语言模型训练中,用了什么训练数据从来没有模型厂真正公开,但这个问题大致有这么两个共识; a.公共语料库有百科、代码库、Common Crawl语料库等; b.但公共和标准语料库几乎已被模型训练完毕。
到了2026年,大模型公司开始依赖合成数据和思维连数据。但未来,要给模型投喂更多数据,要么靠自身超快的落地速度去接入更多场景;要么大模型公司本有自有数据,比如说互联网大厂更具数据优势;剩下就是比拼对私有数据的付费能力。
但数据投喂量因涉及数据合规和隐私等,没有模型厂会在报表中展示。真正能体现在报表端的,主要是算力和算法,算法的精进本质是靠人,算力对应的是芯片和云服务。对于这两个问题,我们就一个一个来看一下。
二、人太贵了?不是核心问题!
两个公司员工整体都没超1000人,尤其是Minimax都不足400人;两家公司研发人员都接近75%,单人头月成本6.5-8.5万元人民币(不含期权激励),其中Minimax研发人员单人月成本是16万。
Minimax因人员更为精炼,收入做大过程中,薪资支出至少已能够收入覆盖。而智谱因为商业变现上主要是to B落地,需要匹配更多销售人员;而且研发上对通用模型着力更高,所以人力成本改善并不明显。
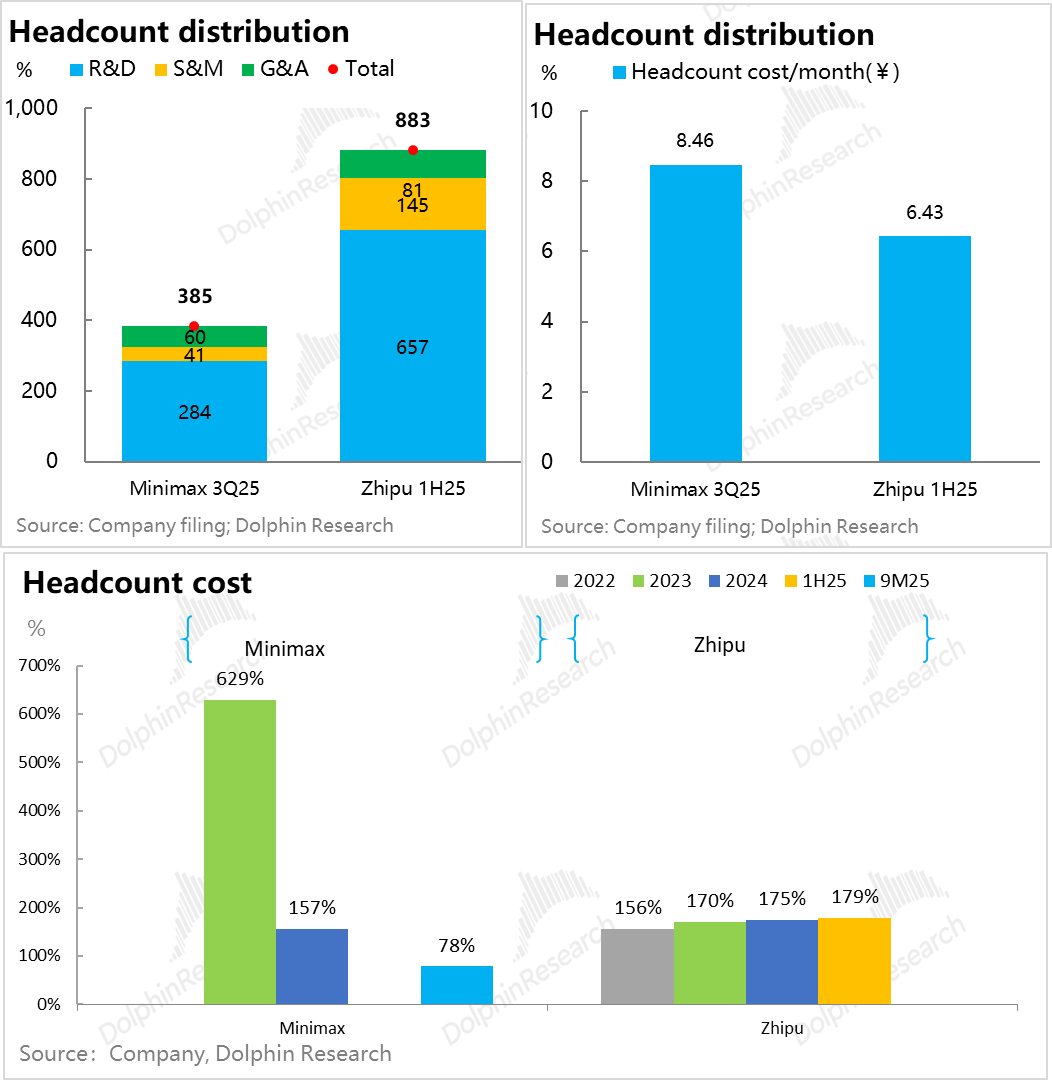
其实,从这两家公司可以看出,大模型在人力上的投入,更多是人才“脑力”密度的投入,而非人力密度的投入。甚至从Minimax的人才密度,可能已经预示了AI时代互联网公司的人力结构雏形:
少而精的大模型研发人才,大量其他的部门岗位都在被模型取代(Minimax旗下AI产品众多,但并未对应超大的人头量),总体薪资呈现出单人薪资超高,但总体可控的状态。
比如Minimax一年总薪资支出大约1亿美金(大约收入的90%上下),考虑到这两家公司基座模型的迭代能力和多模态的发布速度、海外AI动辄上亿美金的抢人战惨烈程度(动辄挖一人开出的薪资就上亿美金),这样的人员支出还不算夸张。
三、核心矛盾:创收 vs 投入,到底能有平衡的时候吗?
虽然薪资成本基本已经把当期的收入“吃光了”。相比于算力投入,人力薪资只是小菜一碟。薪资至少可以随着收入的扩张而有效稀释,但算力投入从两家目前的情况看下来,是一个比收入增长斜率更高的投入类型。
而且从报表上来看,由于Minimax和智谱固定资产开支都非常少,几乎可以确定,两家公司的算力都是使用的第三方云服务,这种相对轻资产的模式,而非OpenAI高度自控数据中心的方式。
大模型公司的报表中,算力的使用都分为了训练算力和推理算力。
模型在训练阶段,就等于要做出来一个可以产生经济效益的商品和服务,需要做研发投入,在产品投用(模型进入推理场景)之前,对应的模型训练支出,都是推出产品之前的“沉淀支出”,计入研发费用当中。
而研发好的模型投入了推理使用场景中,产生的收益记为收入,而推理阶段模型对于算力的消耗,就记为收入创造过程中的直接成本,记在成本项当中。
背后的逻辑也简单:大模型公司砸人、砸算力、砸数据先在实验室里做模型的研发,这个是无论模型是否做出为客户所用,是模型公司都必须要做“沉淀投入”。
只有当模型被研发出来,可以用到推理环节,无论是客户调用模型接口还是自己直接用模型做出来APP来产生收入,才会产生推理收入和推理计算的成本。
这Minimax和智谱两家公司来看,为了研发模型,单单训练算力投入全部占到了总支出的50%以上,是开支的绝对大头,也是妥妥的“吸金黑洞”,贡献了两家公司5-10倍亏损率中的一半以上的支出。
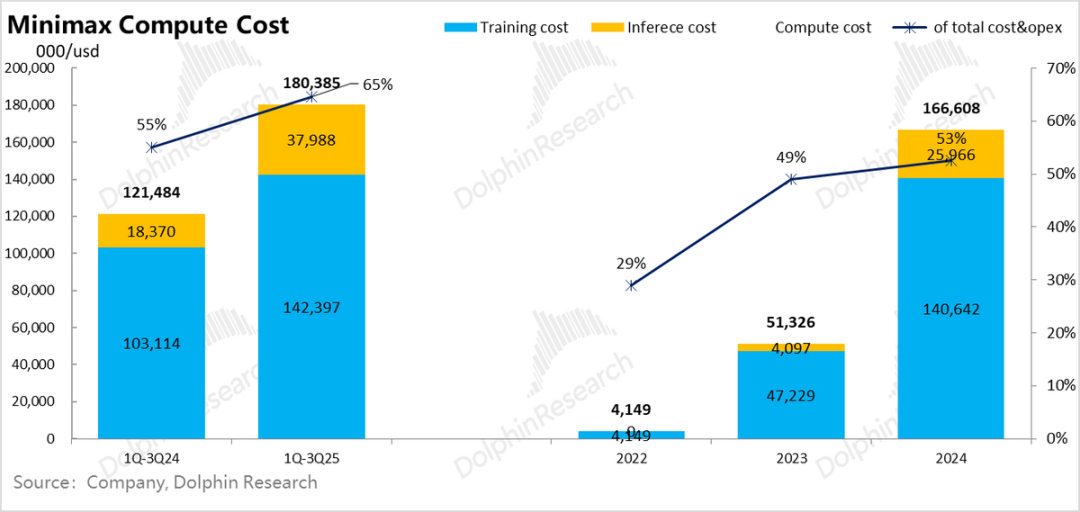
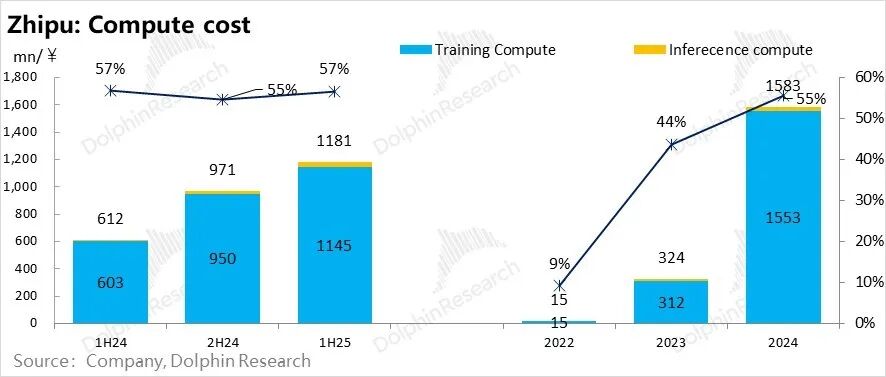
这一占比,直接量化了海豚君在《AI泡沫“原罪”:英伟达是AI戒不掉的“兴奋剂”?》中所说的算力吸空产业链利润的说法。
再拿收入创造和模型训练投入相比,就更能直观感受到训练投入的强度了:
从Minimax来看,2024年创收只有23年模型训练算力投入的65%,25年前三季度虽然收入成长很快,但也对24年同期训练算力成本覆盖能力反而进一步降低到了50%;智谱到25年上半年更是仅有30%的覆盖率。
Minimax由于产品落地上,以海外to C情感AI陪聊为主,设计上有很多游戏和互联网增值的变现模式(详细产品和商业化落地会另外详细分析),to C的互联网规模效应+海外付费能力较强,收入对训练成本情况压力尚小一些。
但智谱的情况就是一个非常明显的收入高增,但对训练成本的回收能力,因为训练成本增长斜率更高,反而越来越弱。
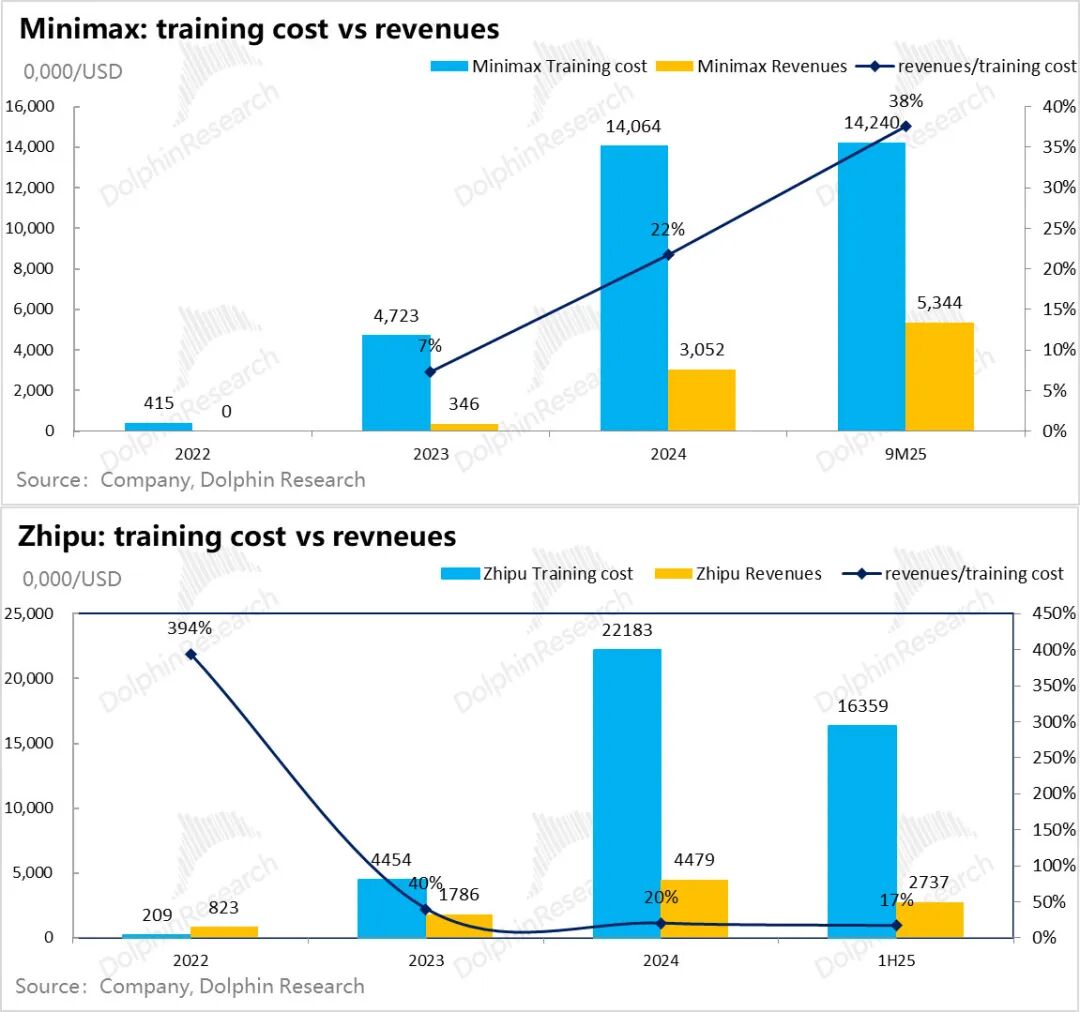
这两年趋势看,虽然两家作为中国独立模型公司的佼佼者,收入增长斜率都很高,但当年创收对上一年研发投入的代偿全都不尽如人意。
这两年趋势看,虽然两家作为中国独立模型公司的佼佼者,收入增长斜率都很高,但当年创收对上一年研发投入的代偿全都不尽如人意。
模型要优秀,训练成本就越高;收入跑得再快,也跟不上一代更比一代高的模型投入。那么矛盾来了,模型越做越亏,这种生意如何理解商业价值?
四、大模型到底是怎样的商业模式?
大模型动辄1000%的亏损率,再次形象地说明了它的研发是一个人才+算力+数据三重密集的商业模式。
强投入和快迭代的共振,在海豚君看来,本质上是把一个强资产负债表的资金密集性业务,做成了“全长在”利润表上的生意。
而当它具备长期的经济和商业价值的时候,就是模型回归成真正的“资产负债表”业务——模型不再需要年年投,而是投一年的训练成本可管之后10年甚至20年,让模型持续产生收入。这个时候,训练成本可以做长期摊销的时候,也只有这样,模型研发的训练成本才会有研发资本化的真正商业基础。具体来看:
1)算力:节节高的“固定资产投入”
Minimax和智谱为例,23年研发一代模型,训练成本要四、五千万美金之间; 而下一代模型的训练要实现代际的线性差异,在数据量、模型参数量和算力投入反而是指数级的提升。最终算力效率提升,反而拉高了算力的总需求量。
从这两家公司来看,模型升级一代,训练成本基本要提高3-5倍。
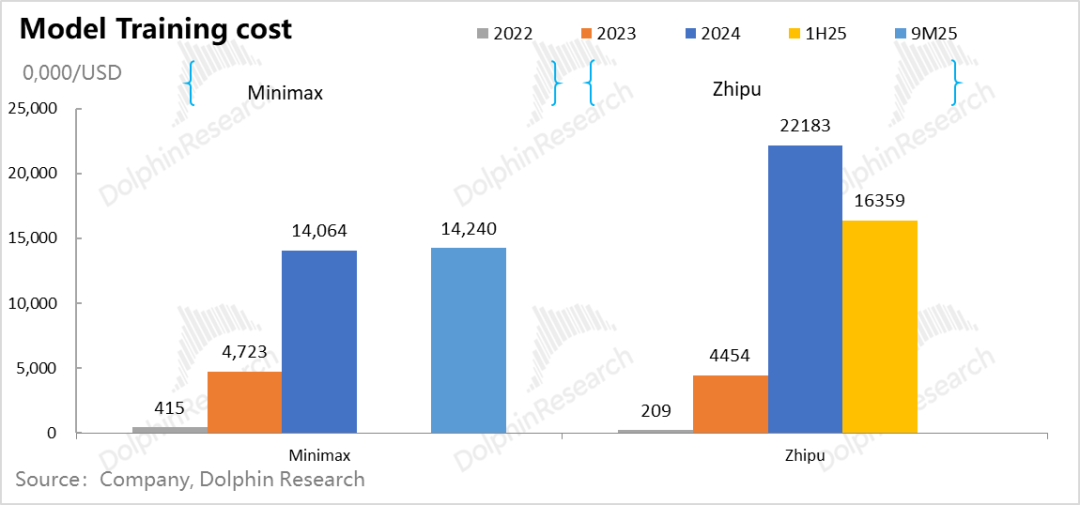

当下大模型的竞争节奏,基本都是一年出一代模型。也就是说之前一年训练出的模型,只对应接下来一年的推理创收期。
这么高的算力投入,没有办法做摊销折旧,只能全部计入当期的研发费用当中,结果就是上文高于收入5-10倍的亏损这种 “惨不忍睹”的亏损率。
2)快迭代:收入vs 投入,追不上的“猫鼠游戏”?
智谱和Minimax两家公司面临的共同情况都是,模型的创收能力尚且覆盖无法模型的算力投入。虽然收入跑不过训练成本,一边狂亏一边狂投,几乎是研发大模型必然的宿命。
为了让自己活到黎明时刻,公司要把这代模型的创收,再考虑上研发薪资支出,几乎要再贴上高于收入3-5倍的融资资金,才能为下一代的模型研发续命,以保证模型不被市场淘汰。
而这样一直滚雪球下去,就是一个收入一直追不上未来投入;且只要还在大模型竞争的牌桌上,就需要不断融资,而且越做大、融资窟窿越大的“资本比拼”游戏。
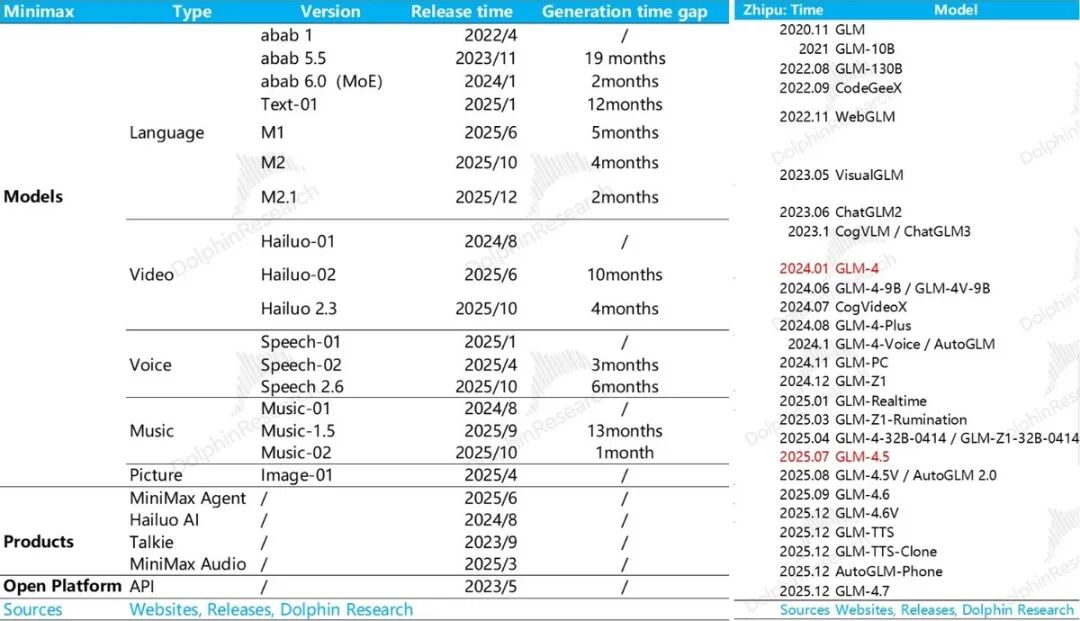
3)缩放定律失效:资本游戏结束?
一个自然而然的问题是,这么下去,到底什么时间才是个头?很显然,在成本端投入巨大的情况下,这里矛盾的核心已不是简单的收入成长速度能否匹配训练成本增速的问题,更加重要的问题是,什么时间模型不需要这么大的投入,或者迭代速度不需要这么快了。
对于大模型技术本身而言,不需要投入的时候,其实就是缩放定律(scaling law)失效的时候,换句话说,当增加一点点的智力所需要的算力开始暴涨式上升的时候,模型训练的必要性就不大了。
模型不再需要高频的训练来迭代,也意味着高密集的训练重资产投入告一段落。算力投入一代新模型后,这代模型能有10年甚至更长的时间来创收。甚至当模型不再需要训练投入,但大模型能够一直创收,这时一个类似“长江电力”的商业模式也就呼之欲出了。
但这个假设的基本前提是,头部大模型厂商在长期的资本、人力和数据消耗战中,已经熬死了一众对手,仅剩的几个对手之间达成默契,不再打价格战,最终形成类似当下云服务市场一样、市占率高度集中的寡头市场,那么大模型的商业模式自然也就立住了。
4)终局之前,是残酷的资本游戏
但缩放定律失效时刻到来之前,大模型公司会是持续的吞金兽。这种情况下,商业模式的竞争本质上就变成了一场持续融资的资本竞赛。
当然,如果像蔚来一样,真有大模型公司能把融资做成一种差异化的生存能力,确实也是一项核心技能。但对于大多数公司而言,融资不是博傻游戏,资金愿意融资,本身是要看企业的产品和执行能力,能融到资金,而且估值越来越高,本身也是一个双向选择的过程。
按媒体报道,中国的模型之战,也已经从刚开始的百模之战走到基模五强——字节、阿里、阶跃、智谱和DeepSeek。
原本的模型创业“六小龙”阶跃、智谱、MiniMax、百川智能、月之暗面与零一万物中,在DeepSeek一夜爆红并用完全的开源颠覆了模型收费之后,零一万物和百川智能已经掉队。
海外同样也已经变成五虎争霸:OpenAI、Anthropic、谷歌Gemini、xAI和 Meta Llama,甚至Meta的模型也已经落后。
一些能够持续融资且估值能够水涨船高、有一些在快速的死在了半路上。从大模型生存的路径来看,融资能力背后真正的是核心人才、模型实力和产品落地进度能力综合作用的结果。
核心人才是AI的上亿美金抢人大赛,这个还是持续进行中,而另外两个一个看模型本身智能化程度,而另外一个最终要落地到创收能力上。
1)模型实力:
从下文可以看到,模型创业公司能生存下来,大多在模型的榜单上能找得到名字,这背后是模型在各个细分颗粒度上(模型智能化程度、幻觉率、模型参数、回答时首个Token输出前的等待时长等)的竞争相对靠前。
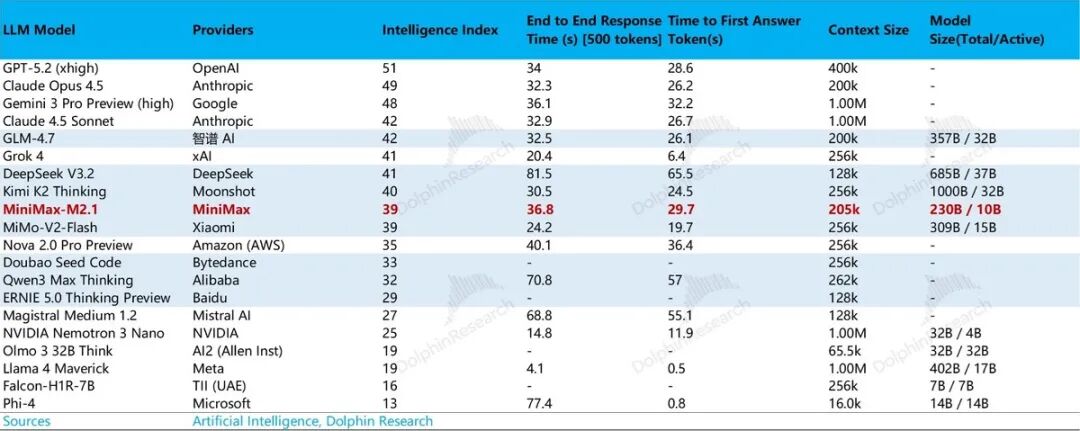
2)产品落地能力
过去一年中,多数独立创业公司,要么在与互联网大厂竞争中被挖走了人,要么产品落地上创收困难,要么是模型价格比拼中,干不过性价比高的开源模型,模型隐没在了半路上。

如果用一句话来概括的话,在Scaling Law撞墙的“黎明时分”之前,甚至到来之后的一段时间内,我们都会看到一个个模型在“人才抢夺、模型研发和产品落地”三维度的比拼中,一个个倒下去。
而真正能走向决赛的,除了看人和背后的资金实力,更加重要的是看模型研发的进度和产品落地的水平。
下一篇分析,海豚君就会围绕智谱和Minimax的模型和产品落地,来理解如何去评价大模型的资本市场价值。
更多精彩内容,关注钛媒体微信号(ID:taimeiti),或者下载钛媒体App







