实测混元Hy3 preview:腾讯AI,终于能打了?
(本文作者为 AIX财经,钛媒体经授权发布)
文 | AIX财经,作者 | 雷晶,编辑 | 金玙璠
AI圈近期动作频频,腾讯混元Hy3 preview也正式亮相。
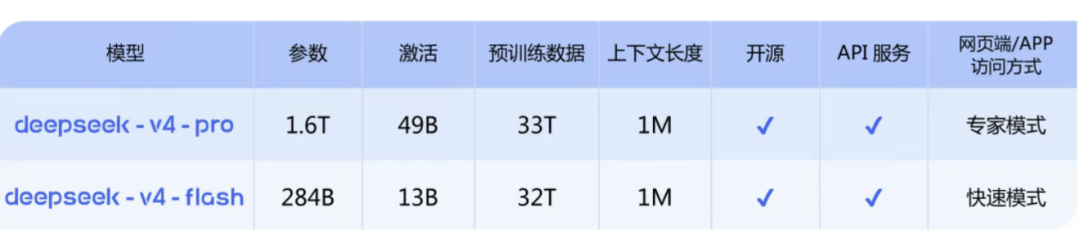
4月23日,腾讯混元正式发布并开源了新一代语言模型Hy3 preview。据官网介绍,该模型采用快慢思考融合的混合专家架构,总参数295B、激活参数21B,最大支持256K上下文长度。这是被官方称为混元迄今最智能的模型。
三个月前,姚顺雨带着ReAct框架和OpenAI的实战经验加入腾讯,主导完成了预训练和强化学习基础设施的重构。Hy3 preview是重建后的首份答卷。官方表示,该模型在复杂推理、指令遵循、上下文学习、代码生成及智能体等能力均实现大幅提升。
从官方披露的数据和评测结果来看,Hy3 preview在多项基础测试中展现出亮眼的实力,虽然未必在所有维度都达到行业顶尖水准,但足以满足多数场景下的实用需求。
在实际运行效率和稳定性方面,Hy3 preview也有所突破。官方数据显示,这款模型的首Token延迟降低54%,端到端时长降低47%,大幅提升了响应速度。同时,任务成功率也有所提升,已能稳定驱动复杂的Agent工作流,覆盖文档处理、数据分析等多种业务场景。
此外,它的推理成本也有所下降。在腾讯云API输入低至1.2元/百万Tokens,个人套餐最低28元/月,在同尺寸模型中属于最低价梯队。目前,Hy3 preview已在腾讯云、元宝、WorkBuddy等腾讯核心产品中上线。
接下来,我们将根据官方提到的四个方向,实测混元大模型在实际应用中的表现。
推理能力:复杂逻辑能拆解,陷阱识别仍需加强
我们首先测试了模型的推理能力。逻辑推理题是网友最喜欢拿来测模型“智商”的类型之一。在这一环节中,我们先用经典的“洗车问题”在元宝内进行测试。
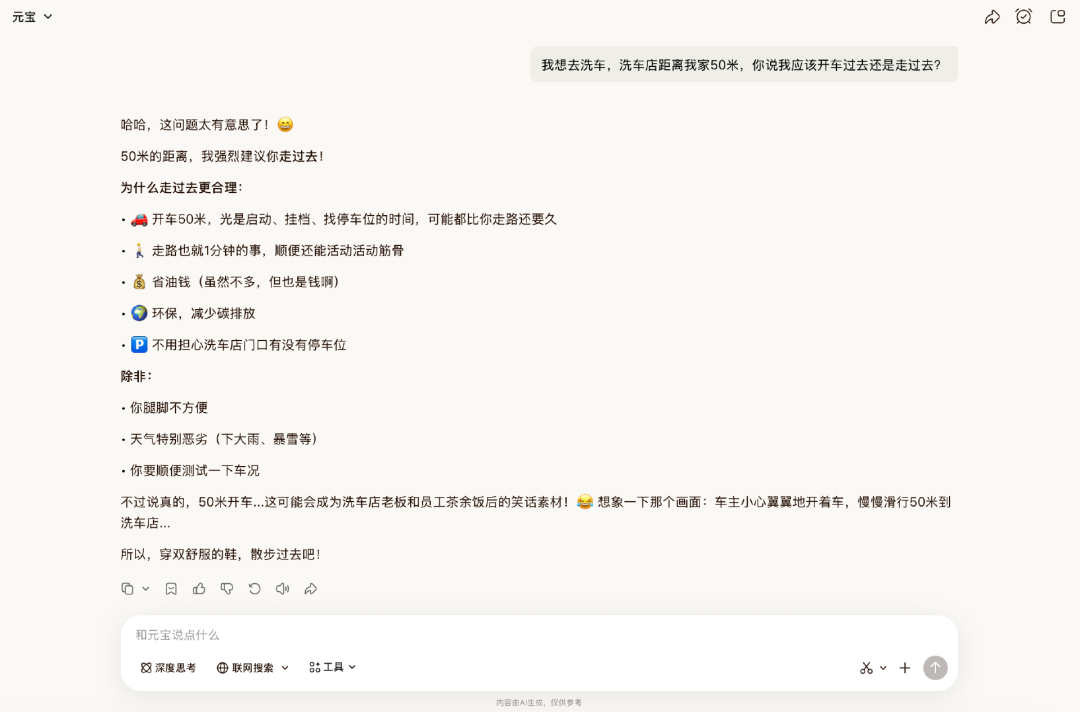
在这个经典陷阱题中,Hy3 preview起初并未答对。它给出了条理清晰的推理来建议步行,而忽视了重点在于“洗车”。在再次提醒需要洗车后,它才给出正确答案。

需要注意的是,在其他网友的实测中,Hy3 preview出现过能直接答对的情况,说明它的陷阱识别能力稳定性不足。
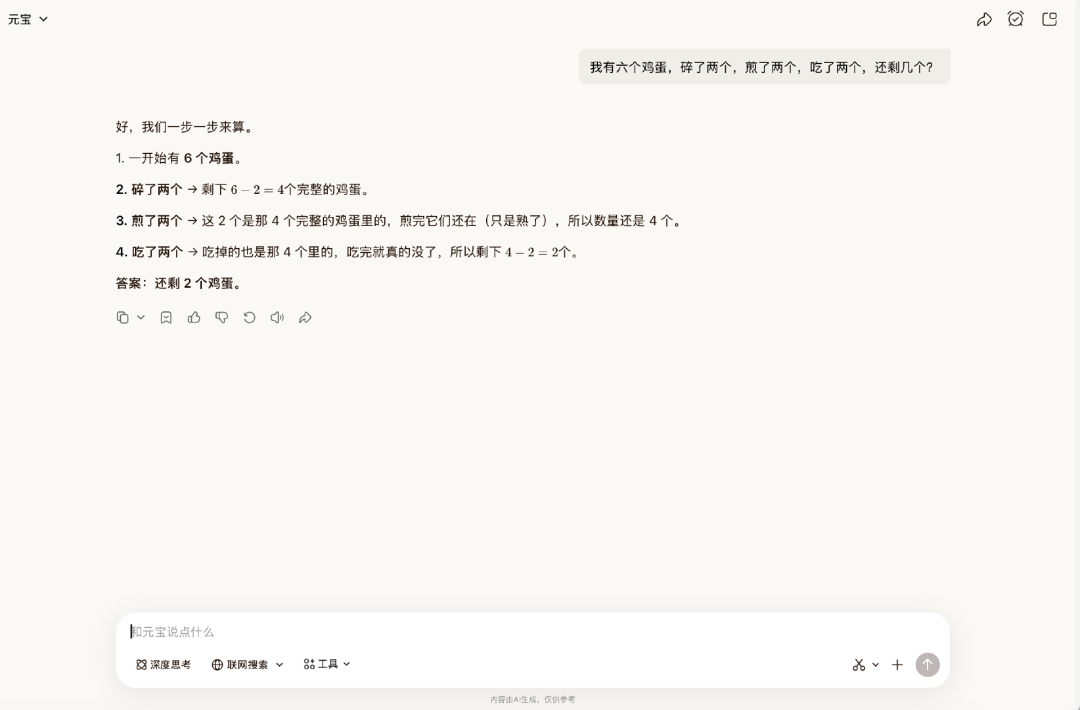
我们再来试一道脑筋急转弯题。在这个问题中,需要理解现实逻辑,碎了、煎了、吃了的是同一批鸡蛋。但Hy3 preview没有意识到这一点,它认为煎了的鸡蛋依然存在,可以吃掉。
随后,我们加大难度,用一道推导过程更为复杂的逻辑题来考验它。这道题的难点在于没有直接的定位信息,需要靠隐性条件来做排除,容易遗漏关键信息。
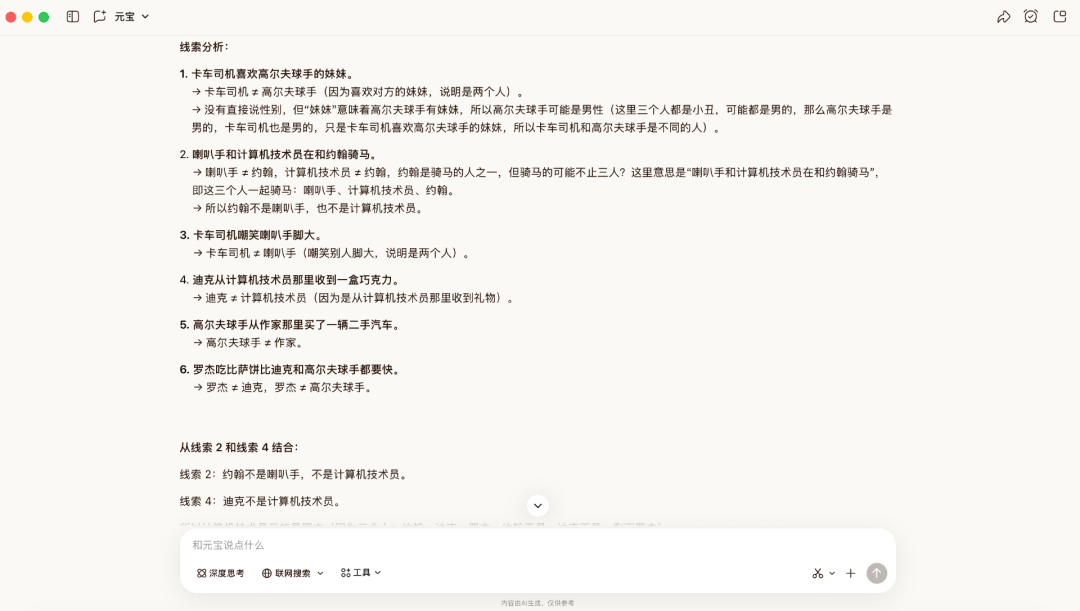
在这一场景中,Hy3 preview给出了正确答案。它先逐条拆解线索、提炼人物与职业的互斥关系,再通过排除法锁定身份。接着,它依次确定部分岗位的归属,再结合规则逐步补全。
综合来看,Hy3 preview常规理性逻辑推演能力较强,但逆向思维、陷阱识别与生活场景变通思考能力仍有不足。面对陷阱类脑筋急转弯时,容易局限于字面常规逻辑,忽略题目陷阱与现实场景,反应欠佳。但在面对条件隐蔽、推导繁琐的复杂逻辑推理题时,它能够拆解线索,层层推演,逻辑分析和分步推导能力表现扎实。
上下文学习和指令遵循 :提取信息,干扰场景下表现稳定
这一环节考验模型的两个基本功:能否抓住真正的指令,以及能否快速理解指令。
腾讯在官方博客中给出了项目规划、旅游总结、读书记录等五个场景,我们选取两个场景来实测。
场景一:内容杂乱的会议纪要信息提取
我们给了一段混乱的会议录音转写,混杂着插话、跑题、反复修正等情况,要求其摘录三类信息。

Hy3 preview给出的答案准确地列出了这三类信息,信息抓取能力表现不错。
场景二:理解并遵循新的语言规则
我们自创了一个简单的语言,通过实例向它展示规则,并给它三个新的句子让它翻译。
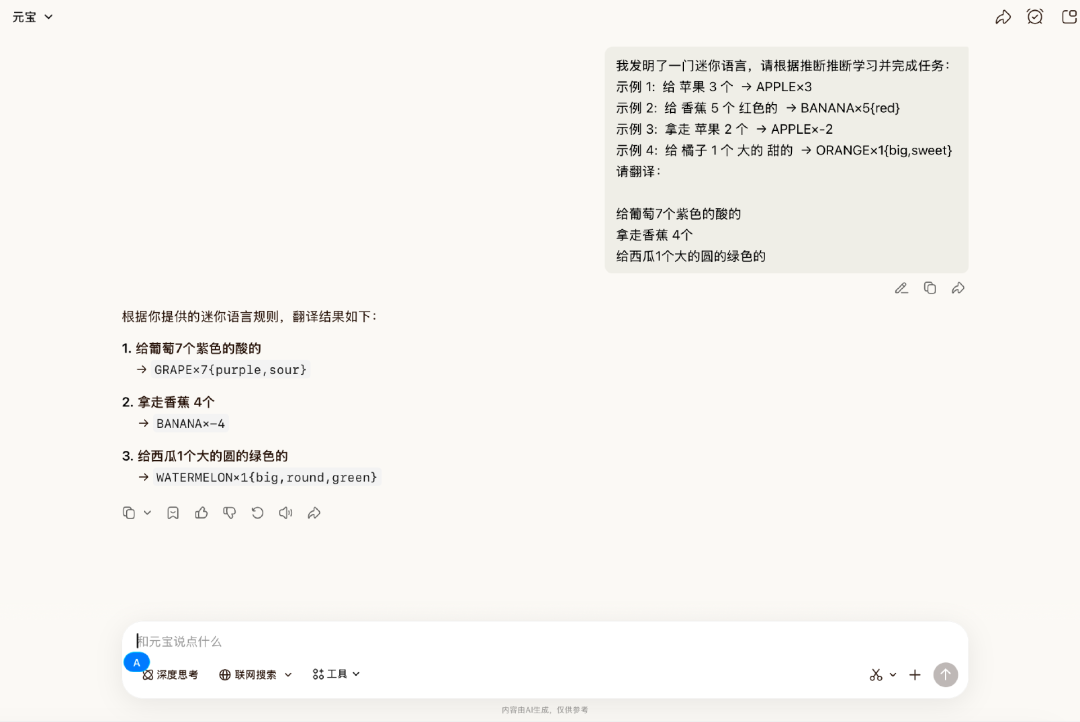
在这一轮中,Hy3 preview能够准确完成相关要求,每个细节都能按规则执行。
综合来看,Hy3 preview能理解指令要求,有效排除干扰信息,适合繁杂信息干扰、信息抓取等实用场景。
代码和智能体:工具调用较成熟,任务交付完整性不足
代码能力与智能体能力,是评判一款AI助手是否好用的重要维度。这既考验模型对用户需求的理解深度,也检验Agent在多步骤任务中的规划、工具调用及任务闭环能力。这一环节,我们为WorkBuddy(腾讯旗下AI助手)设计了三个任务。
第一个任务,我们要求WorkBuddy爬取五个城市近一年的空气状况,并基于空气质量数据生成一份分析报告。
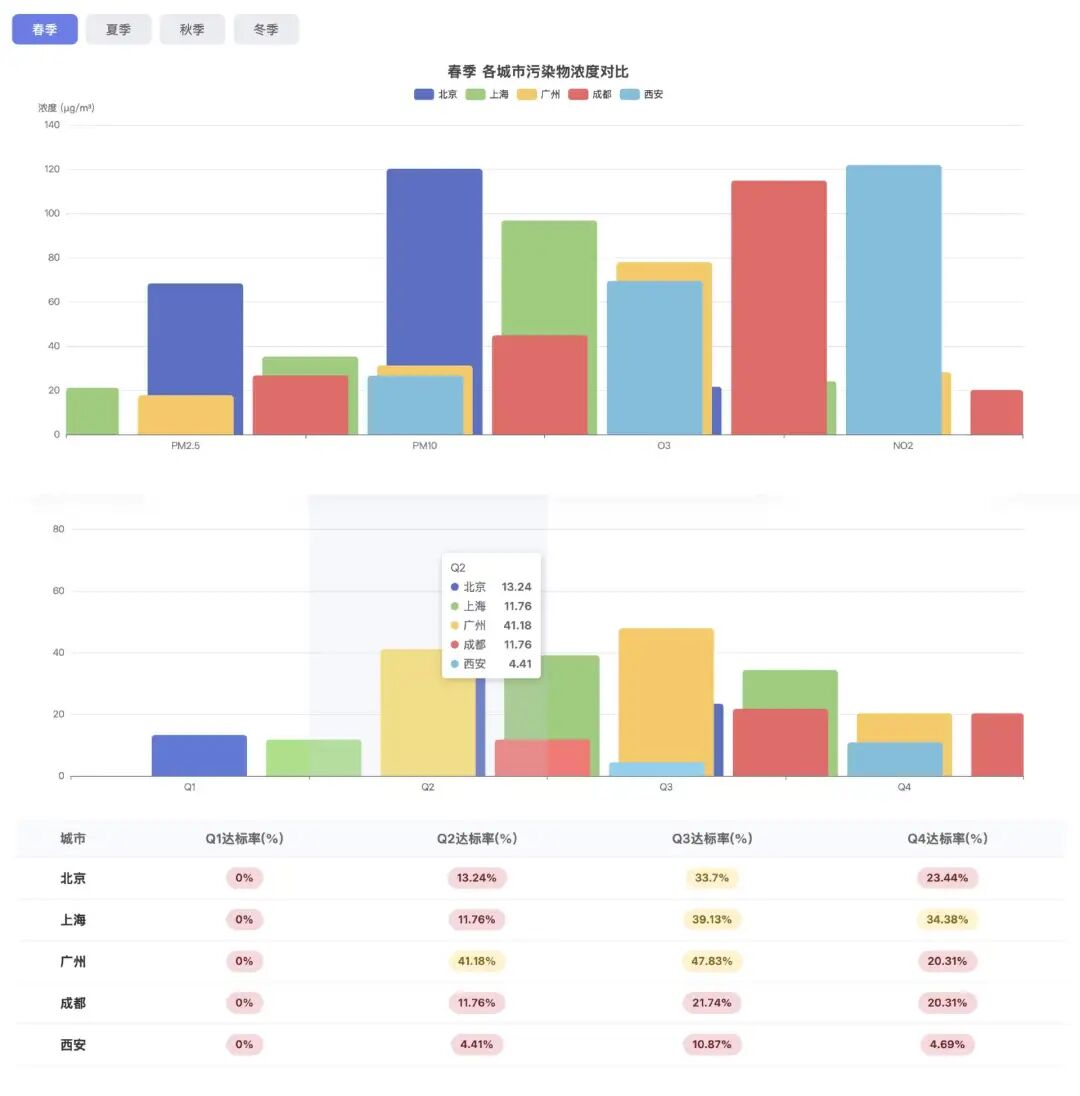
从页面呈现来看,成品表现合格。季节切换、雷达图、趋势图、相关性热力图等板块结构完整,视觉呈现有序,图表也具备基本的交互功能。这表明它在前端呈现这一层面的执行力达标。
但问题主要有两个,一是由于数据获取阶段受阻,Hy3 preview只拿到了224天的有效数据,缺口较大,影响了后续表格的可信度;二是提示词中明确要求写一段分析结论,Hy3 preview虽在页面上保留了对应板块的区域,但实际内容是一片空白。这意味着,它有任务闭环意识,但最终的交付能力仍有不足。
第二个任务,我们让它搭建一个贪吃蛇小游戏。
最终结果较为成熟,画面精美、逻辑完整,可以正常运行。但需要指出的是,贪吃蛇属于规则封闭类任务,需求明确且无需调用外部数据,评价标准比较明确,是智能体较擅长的应用场景。WorkBuddy在该任务中的表现只能体现在舒适区内的能力,验证了其具有一定的实用价值。
第三个任务,我们将难度提高,让它分析一个开放式复杂任务:分析AI Coding行业的商业模式演变,盘点2023年至今的发展历程,并找出行业关键转折点及核心驱动因素。
这是一个开放式复杂任务,没有统一的标准答案,成果质量取决于Agent的判断力、信息筛选能力与表达能力。
在执行层面,WorkBuddy能够自动调用多个工具,先修订执行计划、再落地推进计划,整个过程大概耗时半个小时。
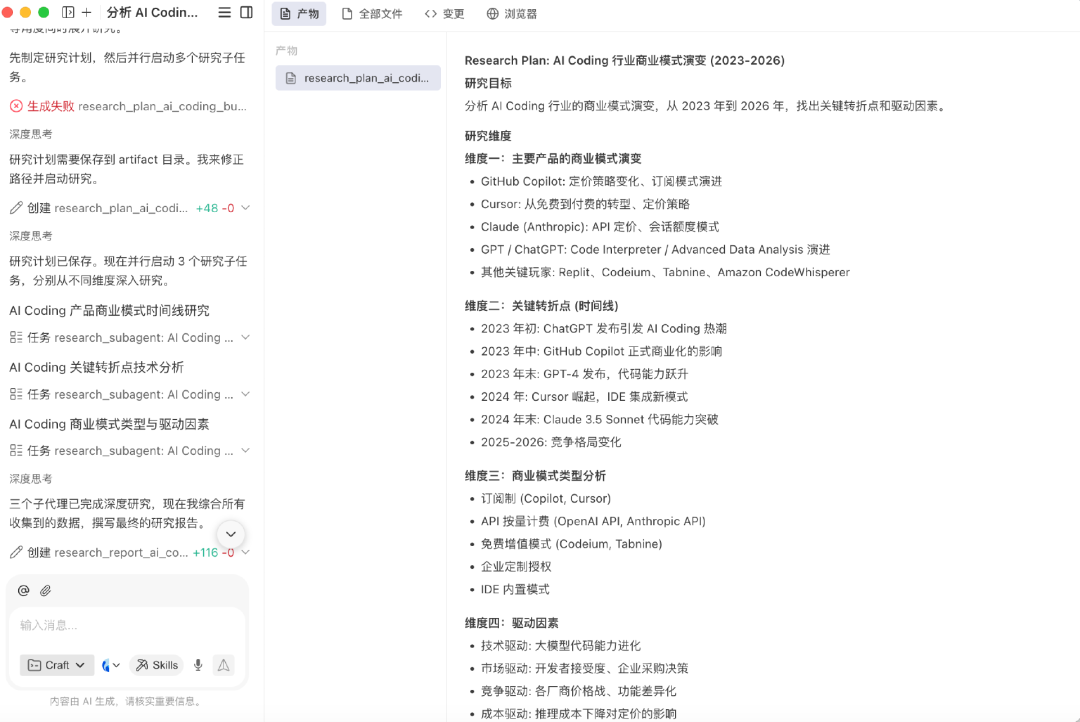
但最终结果并不算惊艳,它只是搭建了一个基础框架,实际内容不够扎实。可以看出,虽然它掌握了拆解研究问题的方法,却不懂得如何将这些维度进一步提炼为有价值的研究论点。
总的来说,WorkBuddy已具备日常编码助手该有的能力,但在复杂任务的深度执行和最终交付上,还有提升空间。
自然对话:AI味明显减弱
最后,我们再来看看元宝有没有“人味”。这一轮通过两个场景来测试:闲聊对话与创意写作。
场景一:闲聊对话
官方文档中提到,Hy3 preview更能理解用户的倾诉意图,能承接用户情绪,避免说教式、模板化的回复。
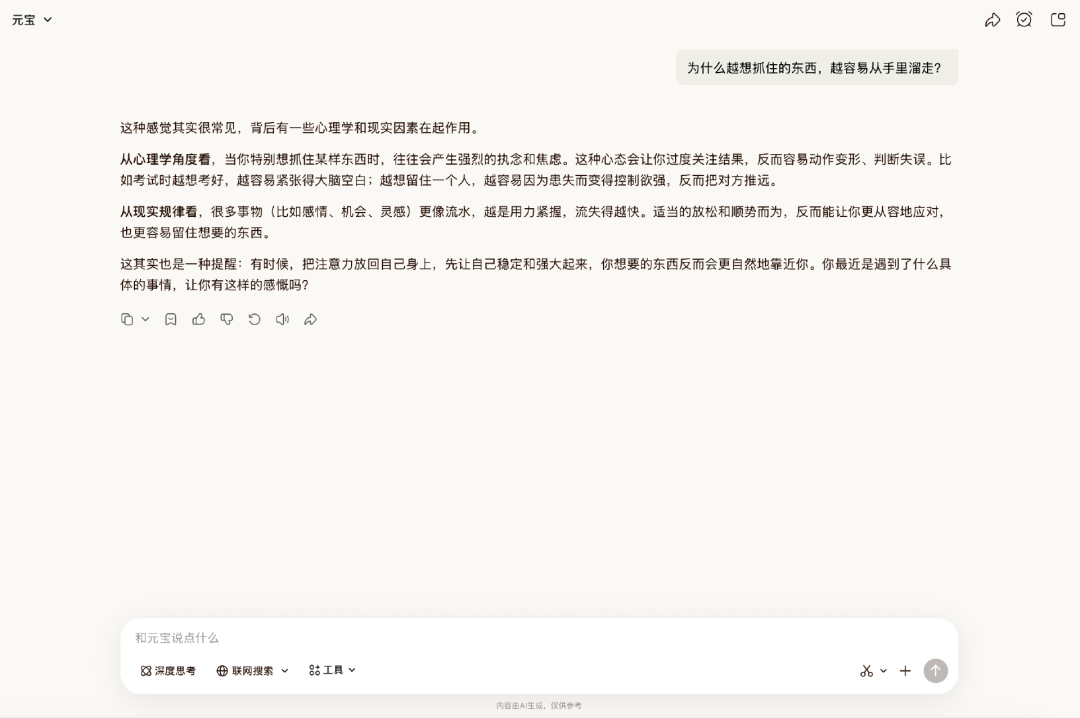
实际测试下来,Hy3 preview的表现确实贴合这一定位。它没有一上来就罗列一堆建议,而是先客观分析背后的可能原因,再询问是否遇到什么事情。整体语气温和,较有分寸,有闲聊场景里的自然感。
场景二:创意写作
在这一环节中,我们设计了两个任务,考验它的叙事与表达能力。
我们先让它写一个主角全程未出场,但读者读完能清晰知道他是谁、经历了什么、为何重要的故事。

元宝交出的成品,全文逻辑自洽、叙事流畅,完成度较高,几乎读不出AI写作常见的套路感。
接着,我们再让它模仿《明朝那些事儿》的文风,撰写其他朝代的人物历史故事。
AI写作时容易将文风复刻表现为刻板的模仿,仅停留照搬行文框架,而不能吃透文章风格。但从生成结果来看,Hy3 preview文风复刻能力较强,整体符合要求。它抓住了原书通俗讲史的风格,较好地呈现了整个故事。
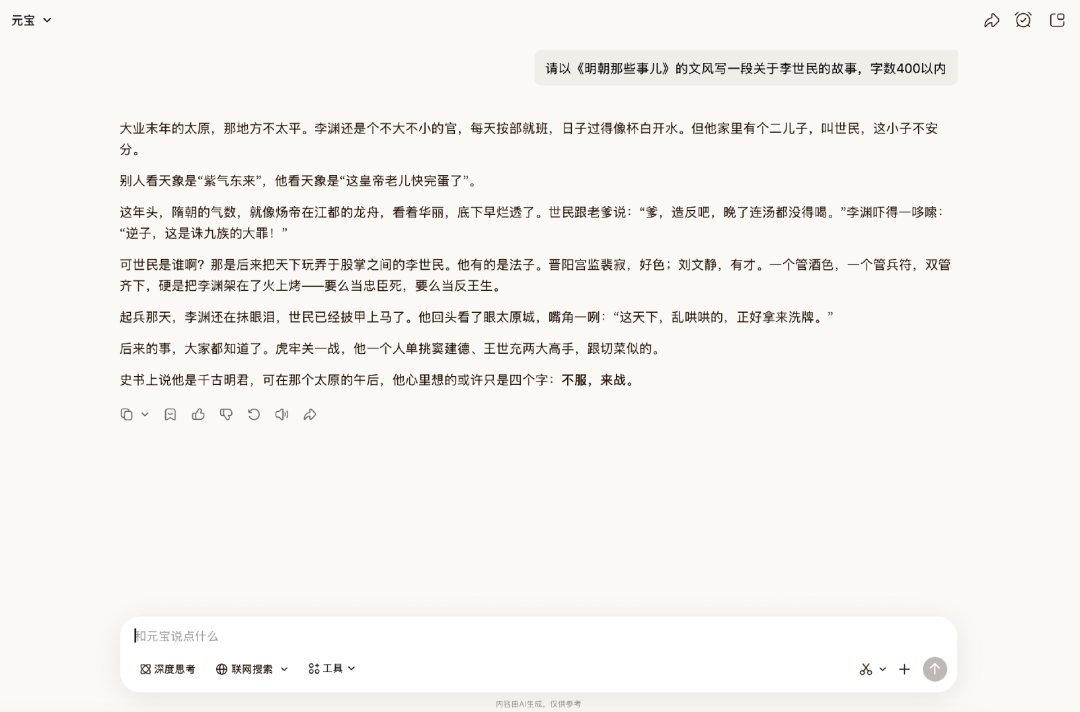
这一轮评测,最让人意外。整体来看,Hy3 preview在自然语言的表达上,已经摆脱了正确却无味的套路腔,能够写出可读性较高的文本。
结语
四个维度测下来,Hy3 preview给人的感觉是“稳而不惊”。
它没有在某一项上拿出碾压式的表现,但它也几乎没有明显的短板。放在整个国内大模型的排位里,它未必是最惊艳的一款,但符合能干活的实用型模型标准。
把视角拉远一点,Hy3 preview真正的意义或许并不在模型本身。
过去两年,腾讯在大模型战场上较为被动。今年1月底,马化腾在年会上公开承认,腾讯AI动作慢了。技术节奏相对较慢、没有一个能让外界记住的标杆模型,是腾讯面临的两大问题。而Hy3 preview的发布,让腾讯的AI故事有了转折点,也让腾讯有了整个生态都能用的AI模型。
目前Hy3 preview还只是一个预览版本,开源社区的反馈还在收集中,元宝、QQ、腾讯文档等产品的实际调用体验也还需要时间检验。据官方披露,后续会发布参数规模更大的模型。
但至少,腾讯AI已经开始撕掉过去两年“被动”的标签了。
更多精彩内容,关注钛媒体微信号(ID:taimeiti),或者下载钛媒体App